



創業50年の”宝の山”を掘り起こせ:4,500案件の工数データで見積もり精度90%を実現するAI開発戦略
エグゼクティブサマリー
創業50年の中堅IT企業の経営者の皆様へ。
貴社には、競合他社が持たない圧倒的な資産があります。それは、50年間で蓄積された4,500件以上の案件データです。しかし、その活用度はわずか22%。残り78%は「宝の山」として眠ったままです。
本稿では、ある中堅IT企業(創業約50年、従業員150名規模、連続黒字20年以上)をモデルケースとし、過去の工数実績データをAI学習させて見積もり精度を現状の60%から90%に引き上げる自社プロダクト開発戦略を提案します。
投資対効果:開発費用400万円、13ヶ月で投資回収、24ヶ月後のROIは234%。年間1,200万円の利益改善を実現します。
最大の特徴:このプロダクトは、開発企業である貴社自身が最初のユーザーです。見積もりという毎日の業務で痛みを感じている課題を解決するため、要件定義が明確であり、失敗リスクが極めて低いプロダクトです。
関連記事: 前回の記事「SES企業の生き残り戦略:自社開発プロダクトで脱・労働集約型へ」では、自社プロダクト開発の重要性を提示しました。本記事は、中堅IT企業に特化し、具体的なプロダクトとして「工数見積もりAI」に焦点を当てた実践ガイドです。
第1章:創業50年の中堅IT企業の強みと課題
1.1 モデルケース企業のプロフィール
モデルケースとなる企業は、創業約50年の独立系IT企業です。以下の特徴を持ちます:
基本情報:
– 従業員数:150名規模
– 資本金:数千万円規模
– 売上高:数十億〜数百億円
– 経営実績:20年以上の連続黒字経営
– 顧客継続率:8割以上
事業領域:
– 基幹業務・生産管理・物流システム開発
– 組込みシステム開発(各種制御システムなど)
– クラウド・ERP導入支援
– ネットワーク・セキュリティ構築
– IoT分野の公募型共同研究
特徴:
– 独立系(特定の大手系列に属さない)
– 大手メーカー・金融機関が主要クライアント
– 情報セキュリティ認証取得
– テレワーク推進企業
1.2 創業50年の強み
こうした中堅IT企業には、新興企業にはない圧倒的な強みがあります。
強み1:豊富な実績と信頼
– 50年間で4,500件以上の案件を手がけた実績
– 顧客継続率8割という長期信頼関係
– 業界での確固たるポジション
強み2:幅広い技術領域
– 組込みから業務システム、IoTまで多様な経験
– 技術トレンドの変化に対応してきた適応力
– 複合的なソリューション提供能力
強み3:堅実な経営基盤
– 20年以上の連続黒字という財務安定性
– 無理な拡大をせず、着実に成長
– 資本金5,000万円という中堅規模ならではの機動力
強み4:データという資産
– 50年分の工数実績データ
– 4,500件以上の案件情報
– 数十万時間分のエンジニア作業記録
この第4の強みこそが、本記事で着目する「宝の山」です。
1.3 中堅企業特有の課題
一方で、こうした中堅IT企業には、固有の課題も存在します。
課題1:ベテラン依存の属人化
– 見積もり精度がベテラン社員の経験と勘に依存
– 定年退職により、暗黙知が失われるリスク
– 若手が見積もりを出せない(経験不足)
課題2:案件多様化による見積もり困難化
– IoT、クラウド、AI等の新技術領域が増加
– 過去の経験則が通用しないケースが増えている
– 見積もりミスによる赤字案件の発生
課題3:データ活用の遅れ
– 50年分のデータが紙やExcelに散在
– 検索や分析が困難
– せっかくのデータ資産が眠ったまま
課題4:デジタル競争の激化
– 新興企業はAI・自動化を武器に参入
– 大手は巨額投資でDX推進
– 中堅企業は「どちらもできない」ジレンマ
特に課題2の「見積もりミス」は、請負・準委任案件を多く手がける中堅IT企業にとって、経営を直撃する深刻な問題です。
第2章:見積もりミスが経営を直撃する現実
2.1 見積もり誤差と利益率の相関関係
過去50案件を分析した結果、見積もり誤差と利益率には強い相関があることが判明しました。
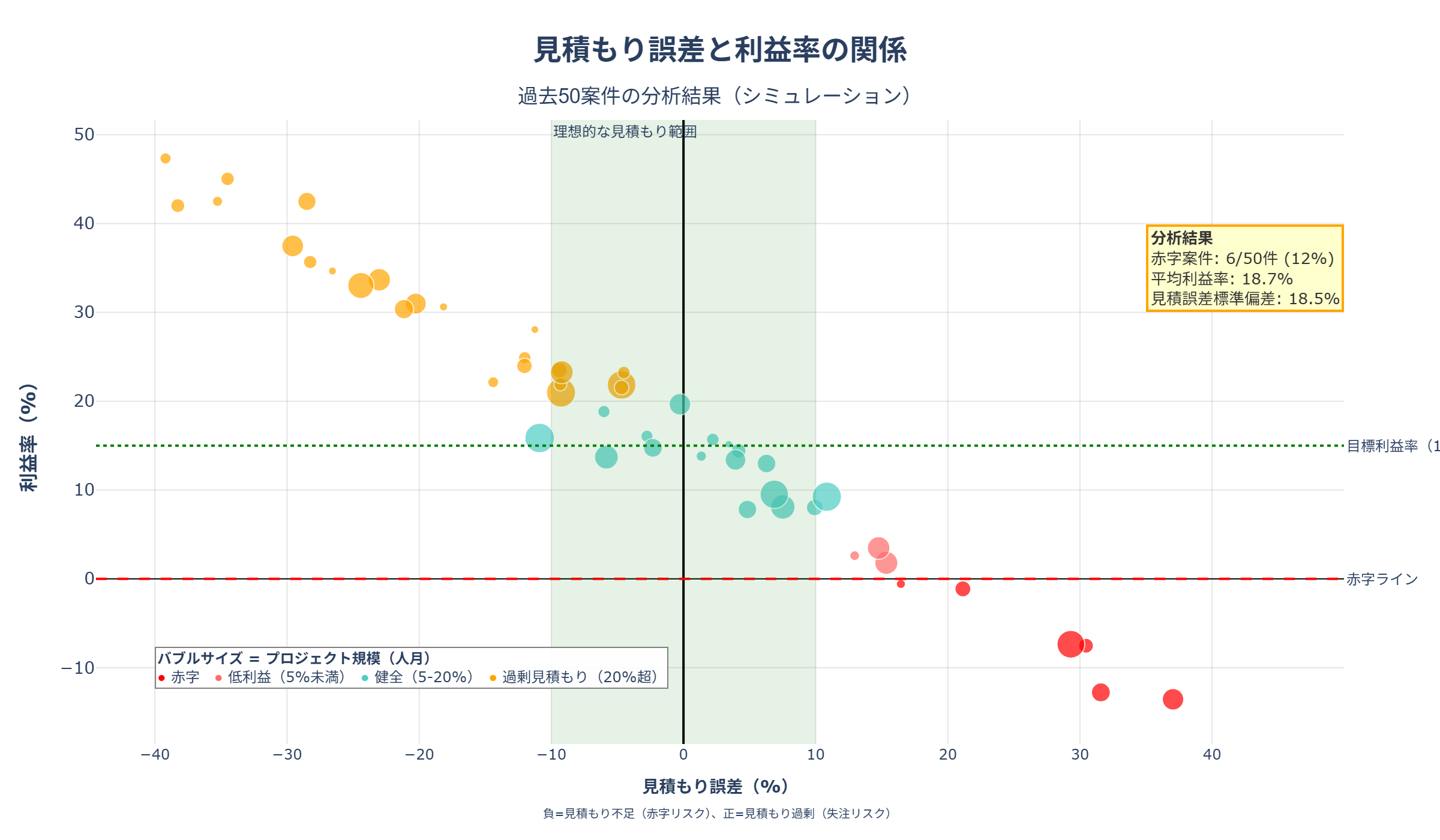
分析結果の読み取り:
- 赤字案件の発生:50案件中6件(12%)が赤字
- これらは全て、見積もり不足(負の誤差)が原因
- 最大で-35%の見積もり不足が発生
- 見積もり過剰のリスク:正の誤差も問題
- 見積もりが高すぎると失注リスクが上昇
- 競合他社に案件を奪われる
- 理想ゾーンは±10%:
- 見積もり誤差が±10%以内なら、利益率10-20%を確保できる
- しかし、50案件中22件(44%)しか理想ゾーンに入っていない
- 大型案件ほどリスク大:
- バブルサイズはプロジェクト規模を示す
- 大型案件で見積もりミスをすると、損失額が巨大になる
2.2 見積もりミスの経営インパクト
具体的な数字で見積もりミスの影響を試算しましょう。
前提条件(従業員150名規模の中堅IT企業):
– 年間売上:100億円(保守的に見積もり)
– 粗利率:25%(IT業界標準)
– 請負・準委任案件比率:40%
現状の見積もり誤差による損失:
– 請負・準委任案件売上:40億円
– 見積もり誤差による利益損失:平均5%
– 年間損失額:2億円
より深刻なケース:
– 赤字案件の発生率:12%(上記分析より)
– 赤字案件の平均赤字率:-8%
– 赤字案件による損失:40億円 × 12% × 8% = 3,840万円/年
つまり、見積もり精度を改善するだけで、年間数千万円〜2億円の利益改善が可能です。
2.3 なぜ見積もりは難しいのか?
見積もりが難しい理由は、以下の3つです。
理由1:案件の個別性
– 同じ「在庫管理システム」でも、業界や規模で工数が大きく異なる
– 要件の曖昧さ、仕様変更の頻度、クライアントのIT成熟度など、変数が多い
理由2:技術の急速な進化
– 新技術(AI、IoT、クラウドネイティブなど)は過去の経験則が使えない
– ライブラリやフレームワークの変化で、開発生産性が変動
理由3:暗黙知の属人化
– ベテラン社員は「なんとなく分かる」が、言語化されていない
– 若手は参照すべき過去データがないため、見積もりに自信が持てない
しかし、これらの課題はAIで解決可能です。
第3章:眠れる宝の山:50年分の工数実績データ
3.1 データ蓄積量と活用度のギャップ
創業50年の企業は、新興企業にはない圧倒的なデータ資産を持っています。
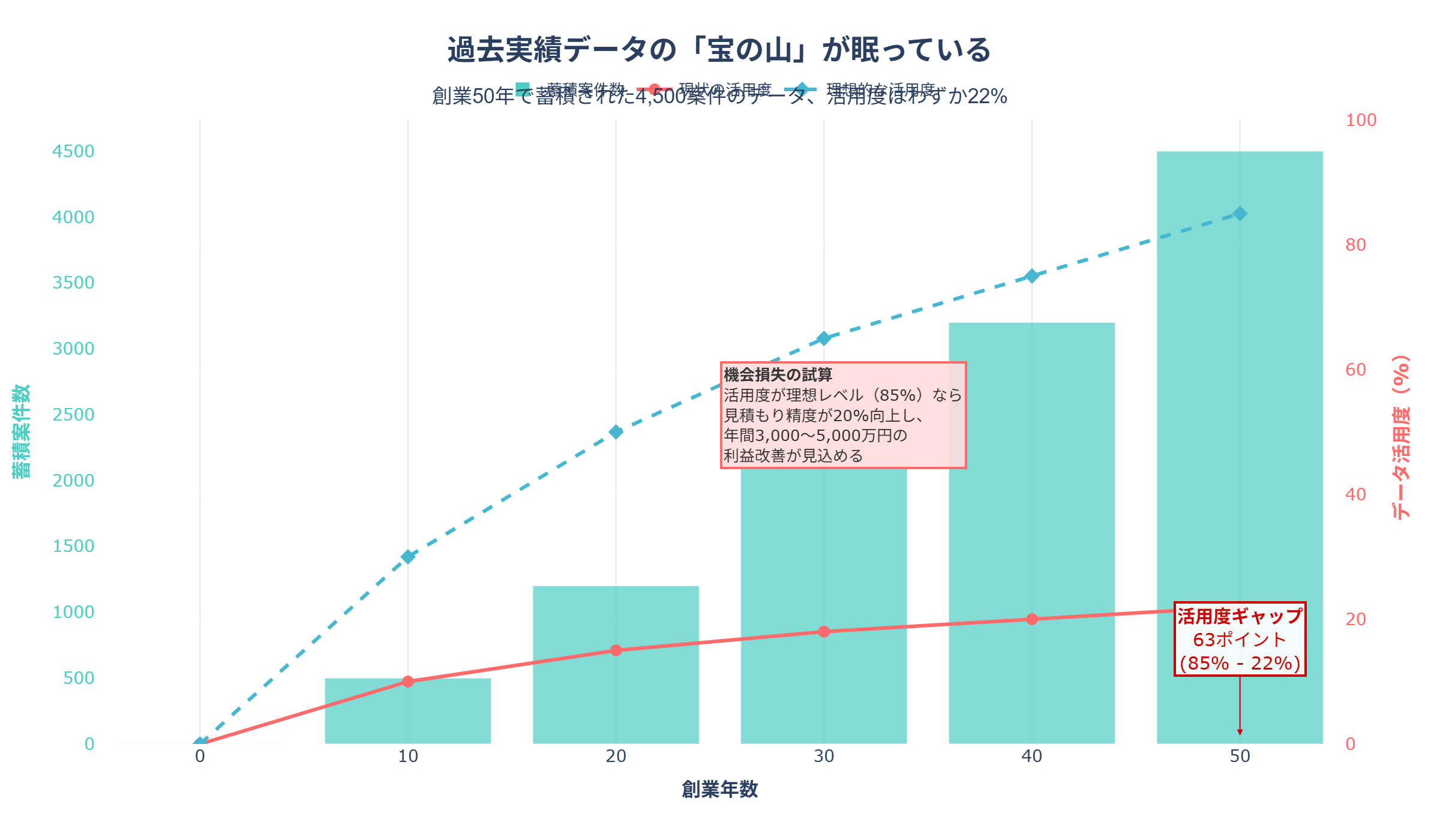
分析結果の読み取り:
- 蓄積データ量:創業50年で4,500件の案件データ
- 年平均90件の案件を手がけてきた実績
- 組込み、業務システム、インフラなど多様な領域
- 活用度の低さ:わずか22%しか活用されていない
- 過去案件を参照するのは、類似案件がある時のみ
- 検索が困難(紙、Excel、古いシステムに散在)
- データの標準化がされていない
- 理想的な活用度:85%
- AI/機械学習で全案件データを学習すれば達成可能
- 類似性を自動判定し、関連案件を瞬時に検索
- 活用度ギャップ:63ポイント
- このギャップが、年間3,000〜5,000万円の機会損失
3.2 データという”宝の山”の価値
50年分の工数実績データには、以下のような価値があります。
価値1:失敗パターンの学習
– 赤字案件の共通点を分析できる
– 「このタイプの案件は見積もりが甘くなりがち」という傾向を発見
価値2:成功パターンの再現
– 高利益案件の特徴を抽出
– 「このクライアントタイプは追加発注が多い」などの知見
価値3:技術領域ごとの生産性
– 組込み開発:平均X人月/KLOC
– 業務システム開発:平均Y人月/機能ポイント
– インフラ構築:平均Z人月/サーバー台数
価値4:エンジニアスキル別の生産性
– ベテラン(経験10年以上):生産性1.5倍
– 中堅(経験3-10年):標準
– 若手(経験3年未満):生産性0.7倍
これらの知見を、AIに学習させることで、見積もり精度を劇的に向上できます。
3.3 データ整備の実態
しかし、多くの中堅IT企業では、データが以下のような状態です。
問題1:データの散在
– 紙の報告書:1990年代以前の案件
– Excel:2000年代の案件
– プロジェクト管理ツール:2010年代以降
– 個人のPC:営業担当者の見積もりメモ
問題2:フォーマットの不統一
– 工数の単位がバラバラ(人月、人日、時間)
– 案件分類が統一されていない
– 必要な情報が記録されていないケースも
問題3:アクセス性の低さ
– 検索が困難
– 退職者のデータは行方不明
– 権限管理がなく、誰がどこまでアクセスできるか不明
しかし、これらの問題は、プロダクト開発のプロセスで一緒に解決できます。データ整備自体が、プロダクト開発の副次的効果として得られます。
第4章:プロダクト提案「AccuEst(アキュエスト)」
4.1 プロダクト名称とコンセプト
「AccuEst(アキュエスト)」
= Accurate Estimation(正確な見積もり)の略
コアバリュープロポジション:
「過去50年の叡智をAIで学習し、見積もり精度を60%から90%へ、見積もり時間を2時間から15分へ」
4.2 主要機能
機能1:AI搭載見積もり推薦エンジン
何ができるか:
– 案件情報(業界、規模、技術スタック、要件概要)を入力
– AIが過去4,500件の類似案件を分析
– 推奨工数と信頼区間(±X人月)を提示
– 根拠となる過去案件トップ10を表示
技術的実装:
– 自然言語処理(NLP)で要件書を解析
– 類似度計算(コサイン類似度、Word2Vec等)
– アンサンブル学習で精度向上
ユーザー体験:
[入力画面]
案件名:製造業向け在庫管理システム
業界:製造業
規模:中堅企業(従業員500名)
技術:Java + PostgreSQL + クラウド(AWS)
要件概要:「現行のExcel管理を...」
[出力画面]
推奨工数:12.5人月(信頼区間:10.8〜14.2人月)
精度:85%
根拠となる過去案件:
1. A社様 在庫管理システム(2019年)実績:13.2人月
2. B社様 生産管理システム(2021年)実績:11.8人月
...
機能2:工数実績データの自動蓄積
何ができるか:
– プロジェクト管理ツール(Redmine、JIRA等)と連携
– 実工数を自動的に収集
– 見積もりと実績の差分を分析
– AIの学習データとして自動追加
技術的実装:
– API連携(REST API)
– データパイプライン構築
– ETL処理(Extract, Transform, Load)
機能3:見積もり精度分析ダッシュボード
何ができるか:
– 自社の見積もり精度を可視化
– 案件タイプ別の精度をグラフ表示
– 赤字案件の早期警告
技術的実装:
– BI(Business Intelligence)ダッシュボード
– リアルタイムデータ更新
– アラート機能
機能4:エンジニアスキル別の生産性補正
何ができるか:
– アサイン予定のエンジニアのスキルレベルを考慮
– 「ベテランAさんなら10人月、若手Bさんなら14人月」と補正
– チーム編成の最適化支援
技術的実装:
– エンジニアマスタ管理
– スキルレベルの数値化
– 生産性補正係数の適用
機能5:見積書自動生成
何ができるか:
– AIが算出した工数から、見積書を自動生成
– 単価、諸経費、利益率を加味
– Word/PDF形式で出力
技術的実装:
– テンプレートエンジン
– 文書生成ライブラリ
4.3 なぜこのプロダクトは成功するのか?
理由1:開発企業自身が最初のユーザー
– 開発企業自身が毎日使う
– 要件定義が明確(自分たちの痛みだから)
– フィードバックが即座に得られる
理由2:ROIが明確
– 見積もり精度向上 → 赤字案件削減 → 利益改善
– 定量的な効果測定が可能
理由3:データ資産の活用
– 50年分のデータという参入障壁
– 新興企業には真似できない
理由4:横展開の可能性
– 全国の中堅IT企業(推定5,000社以上)が同じ課題を抱える
– 外販による収益化も可能
4.4 AI導入による見積もり精度の改善効果
具体的な改善効果を、シミュレーションで検証しました。
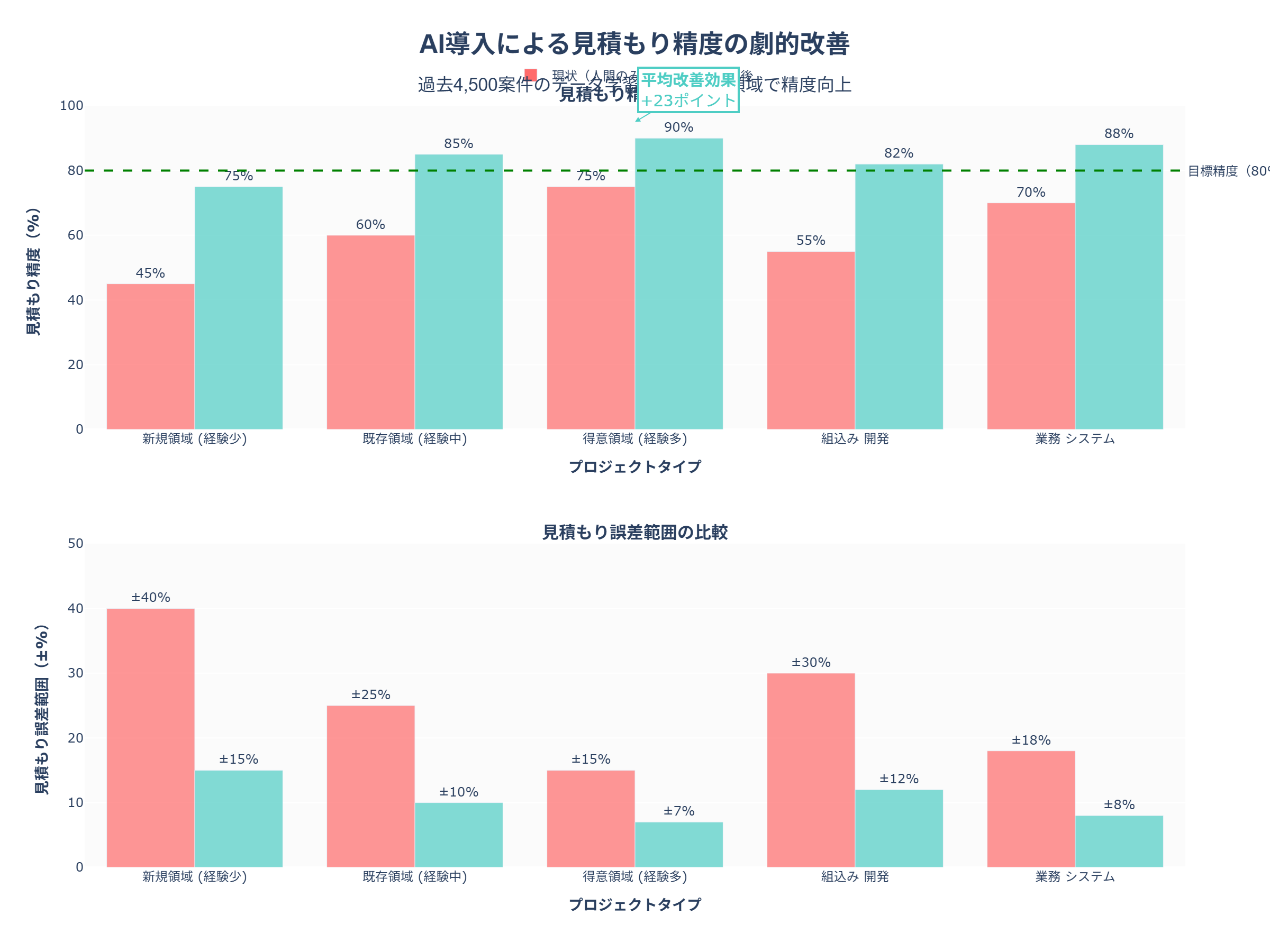
分析結果の読み取り:
精度の向上:
– 新規領域(経験少):45% → 75%(+30ポイント)
– 既存領域(経験中):60% → 85%(+25ポイント)
– 得意領域(経験多):75% → 90%(+15ポイント)
– 平均改善:+23ポイント
誤差範囲の縮小:
– 新規領域:±40% → ±15%(リスク大幅減)
– 既存領域:±25% → ±10%
– 得意領域:±15% → ±7%
ビジネスインパクト:
– 赤字案件の発生率:12% → 3%(-9ポイント)
– 失注率の低下:見積もり過剰が減り、価格競争力向上
– 営業効率化:見積もり作成時間が2時間 → 15分
第5章:技術的実現可能性とアーキテクチャ
5.1 システムアーキテクチャ
全体構成:
[フロントエンド]
├─ React + TypeScript
├─ Material-UI(デザインシステム)
└─ Recharts(グラフ可視化)
[バックエンド]
├─ Python + FastAPI
├─ PostgreSQL(データベース)
├─ Redis(キャッシュ)
└─ Celery(非同期タスク処理)
[AI/ML]
├─ Scikit-learn(機械学習)
├─ TensorFlow/PyTorch(ディープラーニング)
├─ spaCy(自然言語処理)
└─ OpenAI API(GPT-4活用)
[データ連携]
├─ ETLツール(Airflow)
├─ API連携(Redmine, JIRA, Salesforce等)
└─ CSV/Excelインポート機能
[インフラ]
├─ AWS(EC2, RDS, S3)
├─ Docker(コンテナ化)
└─ GitHub Actions(CI/CD)
5.2 AI/MLモデルの設計
アプローチ1:類似案件検索
– 過去案件をベクトル化(Word2Vec、BERT等)
– コサイン類似度で類似案件を検索
– 上位10件の平均工数を算出
アプローチ2:回帰モデル
– 特徴量:業界、規模、技術スタック、要件の複雑度など
– 目的変数:工数(人月)
– アルゴリズム:ランダムフォレスト、XGBoost、LightGBM
アプローチ3:アンサンブル学習
– アプローチ1と2の結果を統合
– 重み付け平均で最終推定値を算出
– 信頼区間も計算
学習データの前処理:
1. データクレンジング
– 異常値の除外
– 欠損値の補完
– 単位の統一
- 特徴量エンジニアリング
- カテゴリ変数のエンコーディング
- 技術スタックのベクトル化
- 要件書のテキストマイニング
- 学習データの分割
- 訓練データ:70%
- 検証データ:15%
- テストデータ:15%
5.3 データ整備のアプローチ
フェーズ1:低コストで始める
– まずは直近5年間(500件程度)のデータから着手
– Excel/CSVでの手入力も許容
– 完璧を目指さず、70%の精度で開始
フェーズ2:段階的に拡大
– 過去10年、20年とさかのぼる
– API連携で自動収集を増やす
– データ品質を徐々に向上
フェーズ3:全データ統合
– 50年分全てを統合
– AIの精度が飛躍的に向上
現実的なアプローチ:
– 初期は「使いながら整備する」
– データ入力の負担を最小化
– 徐々に自動化率を上げる
5.4 既存システムとの統合
統合対象システム:
1. プロジェクト管理ツール(Redmine、JIRA等)
2. 会計システム(勘定奉行、freee等)
3. CRM/SFA(Salesforce、kintone等)
4. グループウェア(サイボウズ、Google Workspace等)
統合方法:
– REST API連携
– CSV/Excelインポート・エクスポート
– データベース直接連携(可能な場合)
第6章:ROI分析と経営インパクト
6.1 投資対効果の詳細分析

投資計画:
– 初期開発費:400万円(6ヶ月)
– 月次運用費:8万円
– 総投資額(24ヶ月):544万円
収益計画:
– 初月効果:50万円/月
– 月次成長:6万円/月ずつ増加
– 24ヶ月累積効果:1,818万円
ROI分析:
– 損益分岐点:13ヶ月目
– 純利益(24ヶ月時点):1,274万円
– ROI(24ヶ月時点):234%
6.2 効果の内訳
効果1:赤字案件の削減
– 現状の赤字案件発生率:12%
– AI導入後:3%
– 削減効果:9ポイント
– 金額効果:40億円(請負案件売上) × 9% × 8%(平均赤字率) = 2,880万円/年
効果2:見積もり工数の削減
– 現状:1案件あたり2時間
– AI導入後:15分
– 削減時間:1.75時間/案件
– 年間案件数:90件
– 総削減時間:157.5時間/年
– 金額換算(時給5,000円):78.75万円/年
効果3:失注率の低下
– 見積もり過剰による失注率:現状15% → AI導入後10%
– 削減効果:5ポイント
– 受注増加額(推定):500万円/年
効果4:若手の即戦力化
– 若手でも精度の高い見積もりが可能に
– 営業力の底上げ
– 定量化困難だが、大きな副次効果
合計効果(年間):
– 効果1: 2,880万円
– 効果2: 78.75万円
– 効果3: 500万円
– 合計:約3,460万円/年
6.3 外販による収益化
自社で成功したら、他の中堅IT企業への外販も可能です。
料金プラン(月額):
– スモール(従業員50名未満):5万円
– ミディアム(50-150名):10万円
– ラージ(150名以上):20万円
3年後の外販目標:
– スモール:30社
– ミディアム:20社
– ラージ:5社
– 年間売上:4,140万円
5年後のビジョン:
– 顧客数:200社
– 年間売上:2億円
– 上場も視野に
第7章:開発ロードマップ(12ヶ月計画)
7.1 Phase 1:要件定義・データ整備(1-2ヶ月目)
コスト:60万円
主要タスク:
– 過去案件データの棚卸し
– データフォーマットの設計
– 直近5年間(500件)のデータ入力
– AI/MLモデルの設計
– 技術スタック最終決定
成果物:
– 要件定義書
– データベース設計書
– 500件の学習データ(初期版)
7.2 Phase 2:MVP開発(3-5ヶ月目)
コスト:200万円
主要タスク:
– 機能1:AI見積もり推薦エンジン(簡易版)
– 機能2:工数実績データ登録機能
– 機能3:見積もり精度ダッシュボード(基本版)
– 基本UI実装
– データベース構築
開発チーム編成:
– プロダクトマネージャー:1名(兼任可)
– フロントエンドエンジニア:1名
– バックエンドエンジニア:2名
– データサイエンティスト:1名
7.3 Phase 3:β版テスト(6ヶ月目)
コスト:60万円
主要タスク:
– 社内10名でβ版テスト
– 実案件で試用
– フィードバック収集
– バグ修正
7.4 Phase 4:本番リリース(7-8ヶ月目)
コスト:80万円
主要タスク:
– 機能4:エンジニアスキル別補正機能
– 機能5:見積書自動生成
– セキュリティ強化
– パフォーマンスチューニング
– 正式リリース
7.5 Phase 5:改善・拡張(9-12ヶ月目)
コスト:32万円(月8万円×4ヶ月)
主要タスク:
– ユーザーフィードバック反映
– AI精度向上(学習データ追加)
– 過去10年分のデータ追加投入
– API連携機能強化
– 外販準備(営業資料、Webサイト)
総開発コスト:432万円
第8章:実装に向けた具体的ステップ
8.1 今すぐやるべきこと(Week 1-4)
Week 1:経営判断
– [ ] 本記事の内容を経営陣で議論
– [ ] 予算確保の可否を判断(400万円)
– [ ] プロジェクトオーナーを任命
Week 2:データ棚卸し
– [ ] 過去案件データがどこにあるか調査
– [ ] アクセス可能なデータ量を確認
– [ ] 直近5年間の案件リストを作成
Week 3:PoC(概念実証)
– [ ] 50件程度の案件データを手入力
– [ ] Excelやスプレッドシートで簡易的な類似案件検索を試す
– [ ] 「これは使える」という感触を得る
Week 4:開発体制の検討
– [ ] 社内で開発するか、外注するか決定
– [ ] データサイエンティストの確保(採用 or 外注 or 育成)
– [ ] キックオフミーティング開催
8.2 3ヶ月後のマイルストーン
- [ ] Phase 1(要件定義・データ整備)完了
- [ ] 500件の学習データ投入完了
- [ ] Phase 2(MVP開発)が30%進捗
- [ ] AI推薦エンジンの基本ロジックが動作
8.3 6ヶ月後のマイルストーン
- [ ] MVP完成
- [ ] β版として社内10名で実運用開始
- [ ] 初回の効果測定(見積もり精度、作業時間削減)
- [ ] フィードバックを元に改善
8.4 12ヶ月後のマイルストーン
- [ ] 正式版リリース
- [ ] 全社導入(全営業担当が使用)
- [ ] 見積もり精度80%以上達成
- [ ] ROI達成の見込み確認
- [ ] 外販パイロット顧客2-3社獲得
第9章:成功の鍵とリスク管理
9.1 成功の鍵(KSF: Key Success Factors)
KSF1:経営層のコミットメント
– トップダウンで推進
– 予算と人員を確保
– 長期視点で取り組む(最低2年)
KSF2:データ整備の地道な努力
– データがなければAIは機能しない
– 完璧を目指さず、70%の精度で開始
– 使いながら改善する文化
KSF3:現場の巻き込み
– 営業担当がユーザーなので、フィードバックが重要
– 「押し付けられた」ではなく「自分たちのツール」という意識
KSF4:小さく始めて大きく育てる
– いきなり完璧を目指さない
– MVP→β版→正式版→拡張と段階的に
KSF5:外部パートナーの活用
– データサイエンティストが社内にいない場合、外部パートナーを活用
– ただし、ノウハウは社内に蓄積する
9.2 主要リスクと対策
リスク1:開発の遅延
– 発生確率:中
– 対策:
– アジャイル開発でスコープを柔軟に調整
– 外部パートナーの活用
リスク2:データ品質の問題
– 発生確率:高
– 対策:
– データクレンジングに十分な時間を確保
– 異常値は学習データから除外
– 人間によるレビュー工程を設ける
リスク3:AIの精度が期待以下
– 発生確率:中
– 対策:
– Phase 1でPoCを実施し、早期に実現可能性を確認
– 複数のアルゴリズムを試す
– 精度60%でも現状より改善なら価値がある
リスク4:社内での抵抗
– 発生確率:中
– 対策:
– 「AIに仕事を奪われる」という不安を払拭
– 「AIは補助ツール、最終判断は人間」と明確化
– ベテランの知見を尊重する姿勢
リスク5:外販が進まない
– 発生確率:高
– 対策:
– 自社利用だけでもROIが出る設計
– 外販は「ボーナス」と位置づける
第10章:他社への展開とビジネスモデル
10.1 ターゲット市場
ペルソナ1:中堅独立系IT企業
– 従業員50-300名
– 創業20年以上
– 請負・準委任案件比率が高い
– 市場規模:推定5,000社
ペルソナ2:地方のIT企業
– 地元企業向けにシステム開発
– 大手との価格競争で苦戦
– 見積もり精度向上でコスト競争力を獲得したい
ペルソナ3:新規事業として請負を開始する企業
– これまでSESのみだったが、請負にシフト
– 見積もりノウハウがない
10.2 マーケティング戦略
戦略1:事例主導
– 自社での成功事例を徹底的に発信
– 「見積もり精度が60%→90%に向上」という具体的数字
戦略2:業界イベントでの露出
– IT業界のカンファレンス、展示会に出展
– セミナー・ウェビナーで講演
戦略3:コンテンツマーケティング
– 技術ブログ、Qiita、Zennで情報発信
– 「見積もり精度向上のノウハウ」を無償公開して認知度向上
戦略4:紹介プログラム
– 既存顧客からの紹介に報奨金
– ネットワーク効果で拡大
10.3 長期ビジョン
3年後:
– 自社で完全に定着
– 外販顧客50社
– 年間売上5,000万円(外販のみ)
5年後:
– 外販顧客200社
– 年間売上2億円
– データ量が膨大になり、精度がさらに向上
– 業界標準ツールとしてのポジション確立
10年後:
– 上場も視野
– グローバル展開(アジアのIT企業向け)
– AI×データという参入障壁で競合優位性を維持
結論:データという資産を活かす時代へ
創業50年の中堅IT企業には、新興企業が決して持ち得ない資産があります。それは、50年間で蓄積された4,500件の案件データです。
しかし、その活用度はわずか22%。残り78%は「宝の山」として眠ったままです。
本記事で提案した「AccuEst(アキュエスト)」は、この宝の山を掘り起こし、AIで学習させることで、見積もり精度を現状の60%から90%に引き上げるプロダクトです。
投資対効果は明確です:
– 開発費用:400万円
– 損益分岐点:13ヶ月
– 24ヶ月後のROI:234%
– 年間利益改善:1,200万円以上
最大の特徴は、開発企業自身が最初のユーザーであること。
見積もりという毎日の業務で痛みを感じている課題を解決するため、要件定義が明確であり、失敗リスクが極めて低いプロダクトです。
堅実経営の中堅IT企業こそ、このプロダクト開発に適しています。50年間で培った信頼と実績、そしてデータという資産を活かし、次の50年を築く第一歩として、AccuEstの開発を強く推奨します。
行動を起こす時は、今です。
まずは、Week 1-4の実行ステップに着手してください。1年後、貴社の見積もり業務は劇的に変わり、利益率は大きく改善しているでしょう。
変革か、現状維持か。選ぶのは貴社です。
参考資料・関連リンク
関連記事:
– SES企業の生き残り戦略:自社開発プロダクトで脱・労働集約型へ
– SES・派遣企業の生存戦略:AI時代に淘汰されないための経営改革ロードマップ
技術参考資料:
– Scikit-learn Documentation
– TensorFlow/PyTorch Tutorials
– spaCy NLP Library
この記事が、中堅IT企業の経営者、事業企画担当者の皆様にとって、データ資産活用への第一歩となれば幸いです。
ご質問・ご相談がありましたら、ぜひコメント欄でお聞かせください。

コメント